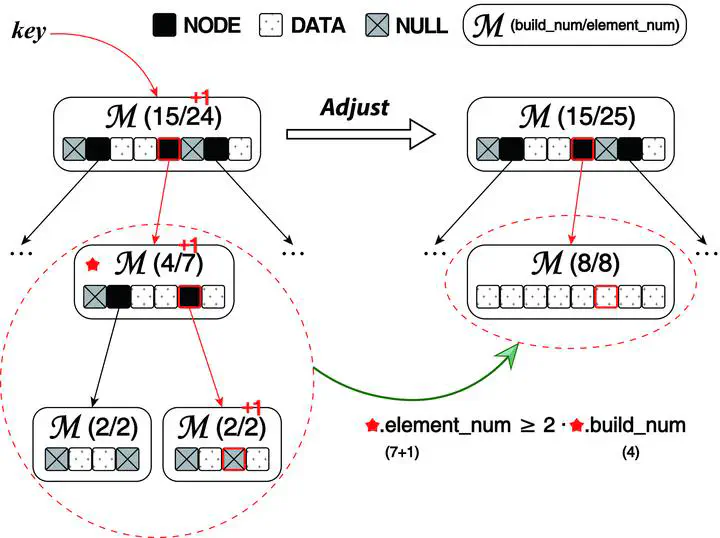
 Architecture of LIPP and Process of Adjustment
Architecture of LIPP and Process of Adjustment
Abstract
Index plays an essential role in modern database engines to accelerate the query processing. The new paradigm of ‘’learned index’’ has significantly changed the way of designing index structures in DBMS. The key insight is that indexes could be regarded as learned models that predict the position of a lookup key in the dataset. While such studies show promising results in both lookup time and index size, they cannot efficiently support update operations. Although recent studies have proposed some preliminary approaches to support update, they are at the cost of scarifying the lookup performance as they suffer from the overheads brought by imprecise predictions in the leaf nodes. In this paper, we propose LIPP, a brand new framework of learned index to address such issues. Similar with state-of-the-art learned index structures, LIPP is able to support all kinds of index operations, namely lookup query, range query, insert, delete, update and bulkload. Meanwhile, we overcome the limitations of previous studies by properly extending the tree structure when dealing with update operations so as to eliminate the deviation of location predicted by the models in the leaf nodes. Moreover, we further propose a dynamic adjustment strategy to ensure that the height of the tree index is tightly bounded and provide comprehensive theoretical analysis to illustrate it. We conduct an extensive set of experiments on several real-life and synthetic datasets. The results demonstrate that our method consistently outperforms state-of-the-art solutions, achieving by up to 4x for a broader class of workloads with different index operations.